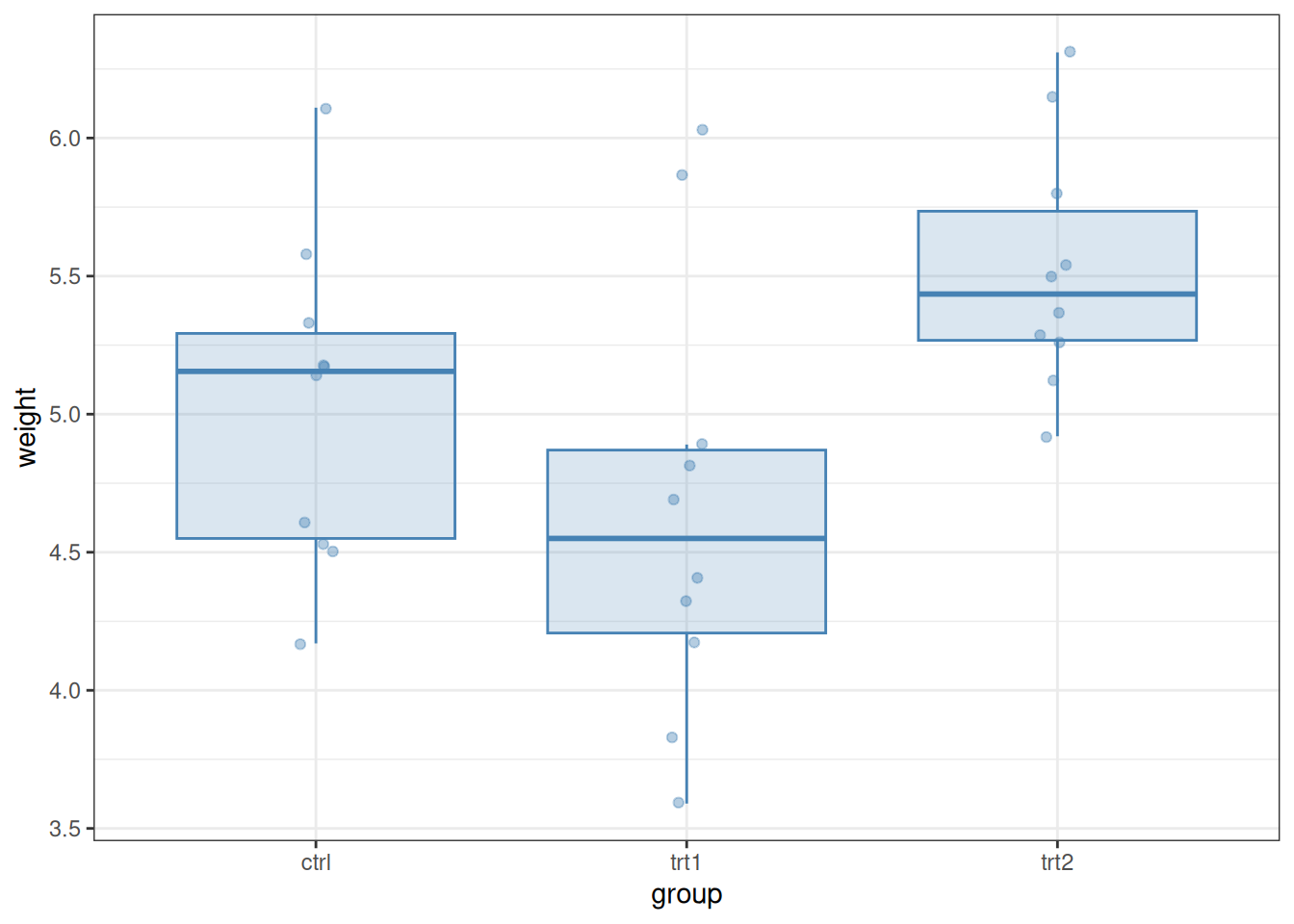
The tools of Chapter 10 allow us to compare two groups of data. But what do we do when we have more than two groups? For example, we might wish to know how different treatments influence plant growth, as measured by dry weight. If there are two treatments, then there will be three (instead of two) groups, because the treatments will be compared with a control group which does not receive treatment.
Such a dataset is in fact built into R, and is called PlantGrowth:
(The PlantGrowth data are in the form of a data frame instead of a tibble; hence we convert it above by using as_tibble.) We see that each group consists of ten observations, and we have three groups: the control (ctrl) treatment 1 (trt1), and treatment 2 (trt2). As usual, we visualize the data first, before doing any tests:
There are two questions one can ask, and they naturally build on each other. First, we might wonder if the observed differences between the distribution of the data in the different groups is meaningful. Could it be that all data points are actually drawn from the same underlying distribution, and the observed differences are simply due to chance? If so, what is the likelihood of that situation? And second, provided we can reject the idea that the data in the different groups are identically distributed, which groups are the ones that differ from one another? For example, based on the figure above, it appears reasonable to expect a real difference between treatment 1 and treatment 2, but it is unclear whether the control truly differs from any of the treatments.
Starting with the first of these questions, there exists an analogue to the Wilcoxon rank sum test which works when there are more than two groups of data. This is the Kruskal–Wallis test, which can be used with any number of groups as long as those groups vary within a single factor.1 The Kruskal–Wallis test is non-parametric, and therefore does not rely on assumptions such as the normality of the residuals. Its implementation in R, kruskal.test, is analogous to wilcox.test, t.testlm, or mblm: it takes a formula and the data as inputs. Therefore, to perform the test on the PlantGrowth data, we write:
kruskal.test(weight ~ group, data = PlantGrowth)
Kruskal-Wallis rank sum test
data: weight by group
Kruskal-Wallis chi-squared = 7.9882, df = 2, p-value = 0.01842
The null hypothesis of the Kruskal–Wallis test is that the observations from all groups were sampled from the same underlying distribution—that is, that there are no differences between the groups other than those attributed to random noise. Consequently, when the p-value is low (like above), this means that it is unlikely that the data in all groups come from the same distribution, and thus that at least one group differs from the others.
Now that we can be reasonably confident about the first question (do all the data come from the same distribution or not?), we can go on to the second: are there differences between particular pairs of groups? One way of finding out could be to perform pairwise Wilcoxon rank sum tests between each pair of groups. This, in fact, would be quite feasible here, because there are only three comparisons to be made (control vs. treatment 1; control vs. treatment 2, and treatment 1 vs. treatment 2). Here are the results of doing this:
as_tibble(PlantGrowth) |># The PlantGrowth dataset, converted to a tibblefilter(group !="trt2") |># Keep only the control and treatment 1wilcox.test(weight ~ group, data = _, conf.int =TRUE)
Wilcoxon rank sum test with continuity correction
data: weight by group
W = 67.5, p-value = 0.1986
alternative hypothesis: true location shift is not equal to 0
95 percent confidence interval:
-0.2899731 1.0100554
sample estimates:
difference in location
0.4213948
as_tibble(PlantGrowth) |>filter(group !="trt1") |># Keep only the control and treatment 2wilcox.test(weight ~ group, data = _, conf.int =TRUE)
Wilcoxon rank sum exact test
data: weight by group
W = 25, p-value = 0.06301
alternative hypothesis: true location shift is not equal to 0
95 percent confidence interval:
-1.00 0.04
sample estimates:
difference in location
-0.49
as_tibble(PlantGrowth) |>filter(group !="ctrl") |># Keep only treatments 1 and 2wilcox.test(weight ~ group, data = _, conf.int =TRUE)
Wilcoxon rank sum exact test
data: weight by group
W = 16, p-value = 0.008931
alternative hypothesis: true location shift is not equal to 0
95 percent confidence interval:
-1.50 -0.31
sample estimates:
difference in location
-0.945
As expected, the difference between the control and the two treatments is not particularly credible (especially in the case of treatment 1), but there is good indication that the difference between the two treatments is not just due to chance.
While this method of using repeated Wilcoxon rank sum tests works fine in our example, there are some problems with this approach. One is that it can quickly get out of hand, because having \(n\) groups means there will be \(n (n - 1) / 2\) pairs to consider. For instance, if the number of groups is 12 (not a particularly large number), then there are 66 unique pairs already. It would not be pleasant to perform this many tests, even if any single test is quite simple to run.
The other problem has to do with multiple testing and its influence on the interpretation of p-values. Very simply put, the problem is that if sufficiently many groups are compared, then we might find at least one pair with a low p-value—not because the null hypothesis is false, but because across a large number of observations some p-values will turn out lower than others just by chance. The p-values measure, in effect, the probability that the observed differences are too stark to be due to simple coincidence. But if we create sufficiently many opportunities for such a coincidence to arise, then of course one eventually will. One of the best explanations of this point is in the following cartoon by xkcd:
Fortunately, there is a way of solving both the problem of automating many pairwise comparisons, as well as adjusting the p-values to account for multiple testing. The way forward is to perform a post hoc (Latin “after this”) test. In this case, the Dunn test is one such post hoc test. This test is implemented in R, but not in any of the basic packages. To use it, one must first install the FSA package:
install.packages("FSA")
Once it is installed, the package should be loaded:
library(FSA)
And then, the Dunn test (dunnTest) follows the familiar syntax of receiving a formula and the data:
The table above is the output of the test, and has four columns. The first column shows which two groups are being compared. The next column, called Z, is the value of the test statistic, which we need not concern ourselves with here. Next, we have the unadjusted p-values; and finally, the adjusted p-values (P.adj), which have been corrected to account for the multiple testing problem mentioned above. Therefore, the adjusted p-values will always be as large or larger than the unadjusted ones.
What has the post hoc Dunn test revealed? Precisely what we have been suspecting: that the only difference worth noting is the one between the two treatments (last row of the table, where the adjusted p-value is sufficiently small to have a chance of pointing at a real difference).
12.2 One-way ANOVA and Tukey’s test
The Kruskal–Wallis test is the non-parametric analogue of one-way ANOVA (ANalysis Of VAriance). The “one-way” in the name refers to the property that there is a single factor indexing the groups, as discussed earlier. ANOVA relies on assumptions such as normality of the residuals and having the same number of observations in each group (balanced design). Otherwise, it is much like the Kruskal–Wallis test.2 Perhaps surprisingly, the function in R that performs an ANOVA is the same lm that we have used in Chapter 11 for performing linear regression:
The output takes some care to interpret correctly: out of the three coefficients listed, (Intercept) is the mean weight in the control group; grouptrt1 is the difference of the mean weight in treatment 1 from the control; and grouptrt2 is the difference of the mean weight in treatment 2 from the control. (We will come back to this, as well as why the lm function was used, in Section 12.3.) To get more information, one can pass the result of lm to a function called anova. Despite its name, the role of this function is not to actually perform the ANOVA (that was done by lm), but to display its results using the sum-of-squares table, which is also known as the ANOVA table. In this table, each factor indexing the groups, as well as their interactions (if present), get one row:
lm(weight ~ group, data = PlantGrowth) |>anova()
Analysis of Variance Table
Response: weight
Df Sum Sq Mean Sq F value Pr(>F)
group 2 3.7663 1.8832 4.8461 0.01591 *
Residuals 27 10.4921 0.3886
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
The p-value above, in the row belonging to the factor group, under the column Pr(>F), is the analogue of the p-value calculated by the Kruskal–Wallis test (which was 0.01842). We can see that the two tests agree qualitatively.
Just as the Dunn test is a post-hoc test for the Kruskal–Wallis test, Tukey’s honest significance test is a post-hoc test for an ANOVA. The corresponding function in R is called TukeyHSD, and it should be applied to the result of the lm function—with one caveat. Tukey’s test requires the output of the ANOVA to be in a particular format. Therefore, before passing the result of lm to TukeyHSD, we first have to pass it to a helper function called aov (“analysis of variance”). Like this:
lm(weight ~ group, data = PlantGrowth) |>aov() |>TukeyHSD()
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = lm(weight ~ group, data = PlantGrowth))
$group
diff lwr upr p adj
trt1-ctrl -0.371 -1.0622161 0.3202161 0.3908711
trt2-ctrl 0.494 -0.1972161 1.1852161 0.1979960
trt2-trt1 0.865 0.1737839 1.5562161 0.0120064
The table is similar to the one produced by the Dunn test, with a few differences. The first column tells us which groups of data are compared. The second column is the raw difference between the group means, the third and fourth are the lower and upper limits of a 95% confidence interval for the difference, and the last one are the p-values (adjusted for multiple comparisons). In this case, the results from the Dunn test and the Tukey test are in agreement: only the difference between the two control groups stands out as having a reasonable chance of being real. The fact that the Kruskal–Wallis test and an ANOVA lead to the same conclusion increases the trust we can place in their results being correct.
The aov function serves no purpose above, except to put the data in a format which TukeyHSD can work with. In case using this intermediary feels like a hassle, one can easily make life simpler, by writing a helper function which automatically calls it, together with the Tukey test:
(See Chapter 3 to review how functions are written.) Here lmFit is a model fit object returned by the lm function. Using this, we can rewrite the above more simply:
lm(weight ~ group, data = PlantGrowth) |>tukey.test()
At first glance, it appears strange that the function performing an ANOVA is the same as the one doing linear regression, lm. Aren’t the two methods very different from one another? After all, ANOVA compares data in different groups, whereas linear regression fits a line to a bunch of data points.
As surprising as it may sound, the two are not different. There is a way of formulating an ANOVA which is exactly analogous to a linear model. To illustrate this idea, let us first consider a dataset with just two groups of data. The fictive bird data from Chapter 10 (fictive_bird_example.csv) will work well:
bird <-read_csv("fictive_bird_example.csv")print(bird, n =Inf)
Let us denote the weight of individual \(i\) by \(y_i\). We wish to predict this based on whether the island is large or small, using a linear model. This can be done in full analogy with Equation 11.1, using the following equation:
On the surface, this is exactly the same equation as Equation 11.1. But there is one important difference: in an ANOVA, we give a different meaning to the \(x_i\). This variable should take on the value 1 if individual i is from the smaller island and the value 0 if it is from the larger island. (It could also be the other way round; it does not matter as long as we choose one convention and stay consistent.) The \(\epsilon_i\) are still the residuals, measuring the deviation of the points from the ideal prediction. What is the “ideal” prediction here? Well, without the \(\epsilon_i\) term, Equation 12.1 reads \(y_i = \beta_0 + \beta_1 x_i\). If individual \(i\) is from the larger island, \(x_i = 0\), and we have \(y_i = \beta_0\). So the intercept \(\beta_0\) corresponds to the mean prediction for the weight of the birds in the larger island. Conversely, if individual \(i\) is from the smaller island, then \(x_i = 1\), and so \(y_i = \beta_0 + \beta_1 \cdot 1 = \beta_0 + \beta_1\). In other words, \(\beta_1\) is the difference in mean weight between the smaller and the larger island.
We can see this in action by running lm and then summary on these data:
lm(weight ~ island, data = bird) |>summary()
Call:
lm(formula = weight ~ island, data = bird)
Residuals:
Min 1Q Median 3Q Max
-9.478 -3.390 -0.199 2.856 14.212
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 22.185 1.143 19.41 <2e-16 ***
islandsmaller -3.024 1.617 -1.87 0.0691 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.112 on 38 degrees of freedom
Multiple R-squared: 0.08431, Adjusted R-squared: 0.06021
F-statistic: 3.499 on 1 and 38 DF, p-value: 0.06914
The intercept, 22.185, is the mean weight on the larger island. To get the mean weight on the smaller one, we must add the intercept to the other coefficient, labelled islandsmaller in the table. That sum is 19.161. Indeed, if we compute the means of the two groups, we get exactly the same answers:
# A tibble: 2 × 2
island mean
<chr> <dbl>
1 larger 22.185
2 smaller 19.161
The rest of the regression table now reads exactly as it would in performing simple linear regression. For example, the p-values are the probability of getting coefficients at least as large as the inferred ones just by chance (assuming normal and independent residuals with equal variance across the groups).
There is just one question left: why was the "larger" island automatically designated as the one corresponding to the intercept? The reason is that R proceeds in alphabetical order, and since "larger" comes before "smaller" alphabetically, it is automatically treated as the intercept (that is, the group corresponding to \(x_i = 0\) instead of \(x_i = 1\)). One can override this by using factors (Section 8.3), in which case the lowest factor level will correspond to the intercept.
So now we have established an analogy between linear regression and ANOVA for the special case when there are only two groups to compare. The main idea was to introduce the indicator variable \(x_i\) which is 1 if observation \(i\) belongs in larger and 0 otherwise. We can rewrite Equation 12.1 with more expressive notation for \(x_i\) and \(y_i\), to make this idea more transparent:
\[
(\text{weight})_i
= \beta_0
+ \beta_1 \cdot (\text{bird is from larger island})_i
+ \epsilon_i
\tag{12.2}\]
What to do when there are more than two groups—say, in the PlantGrowth data where we have three? In that case, we have to introduce one more indicator variable. Say, we could have \((\text{group is trt1})_i\) and \((\text{group is trt2})_i\); the first is 1 if the observation is from treatment 1 (and 0 otherwise), and the second is 1 only if the observation is from treatment 2. If the observation is in the control, then both indicator variables are zero. We can thus write the following equation:
\[
(\text{weight})_i
= \beta_0
+ \beta_1 \cdot (\text{group is trt1})_i
+ \beta_2 \cdot (\text{group is trt2})_i
+ \epsilon_i
\tag{12.3}\]
We can get the usual statistics on them by using summary:
lm(weight ~ group, data = PlantGrowth) |>summary()
Call:
lm(formula = weight ~ group, data = PlantGrowth)
Residuals:
Min 1Q Median 3Q Max
-1.0710 -0.4180 -0.0060 0.2627 1.3690
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.0320 0.1971 25.527 <2e-16 ***
grouptrt1 -0.3710 0.2788 -1.331 0.1944
grouptrt2 0.4940 0.2788 1.772 0.0877 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.6234 on 27 degrees of freedom
Multiple R-squared: 0.2641, Adjusted R-squared: 0.2096
F-statistic: 4.846 on 2 and 27 DF, p-value: 0.01591
Since ctrl comes earliest in the alphabet, it serves as the intercept. Its estimated value, 5.032, is the mean plant weight in the control group. The estimates in the rows grouptrt1 and grouptrt2 (these names were created by mushing together the name of the column in which the factor is found with the factors’ names themselves) are the \(\beta_1\) and \(\beta_2\) coefficients of Equation 12.3, respectively. That is, they are the deviations from the baseline provided by (Intercept). So we can surmise that the estimated mean of trt1 is 5.032 - 0.371 = 4.661, and that of trt2 is 5.032 + 0.494 = 5.526. Indeed, this is what we find relying on simple summaries computing the means in each group:
# A tibble: 3 × 2
group meanWeight
<fct> <dbl>
1 ctrl 5.032
2 trt1 4.661
3 trt2 5.526
It may be clear from the above, but it is good to point out nevertheless, that one does not need to specify the individual indicator variables \((\text{group is trt1})_i\) and \((\text{group is trt2})_i\) and so on by hand. Instead, when defining the model formula as weight ~ group, R automatically assigns them based on the entries of group. It will also automatically name the corresponding coefficients: \(\beta_1\) will instead be grouptrt1 and \(\beta_2\)grouptrt2, in this example. This is very convenient, but it is important to be aware that this substitution is what really goes on under the hood when performing an ANOVA.
More generally, the same procedure can be followed for any number of groups the predictor may come from. For \(n\) groups of data, we introduce \(n-1\) indicator variables which take the value 1 if a data point belongs in the corresponding group, and the value 0 otherwise. Again, R will create these variables automatically, so we do not need to worry about them when defining a linear model.
12.4 Using diagnostic plots on an ANOVA
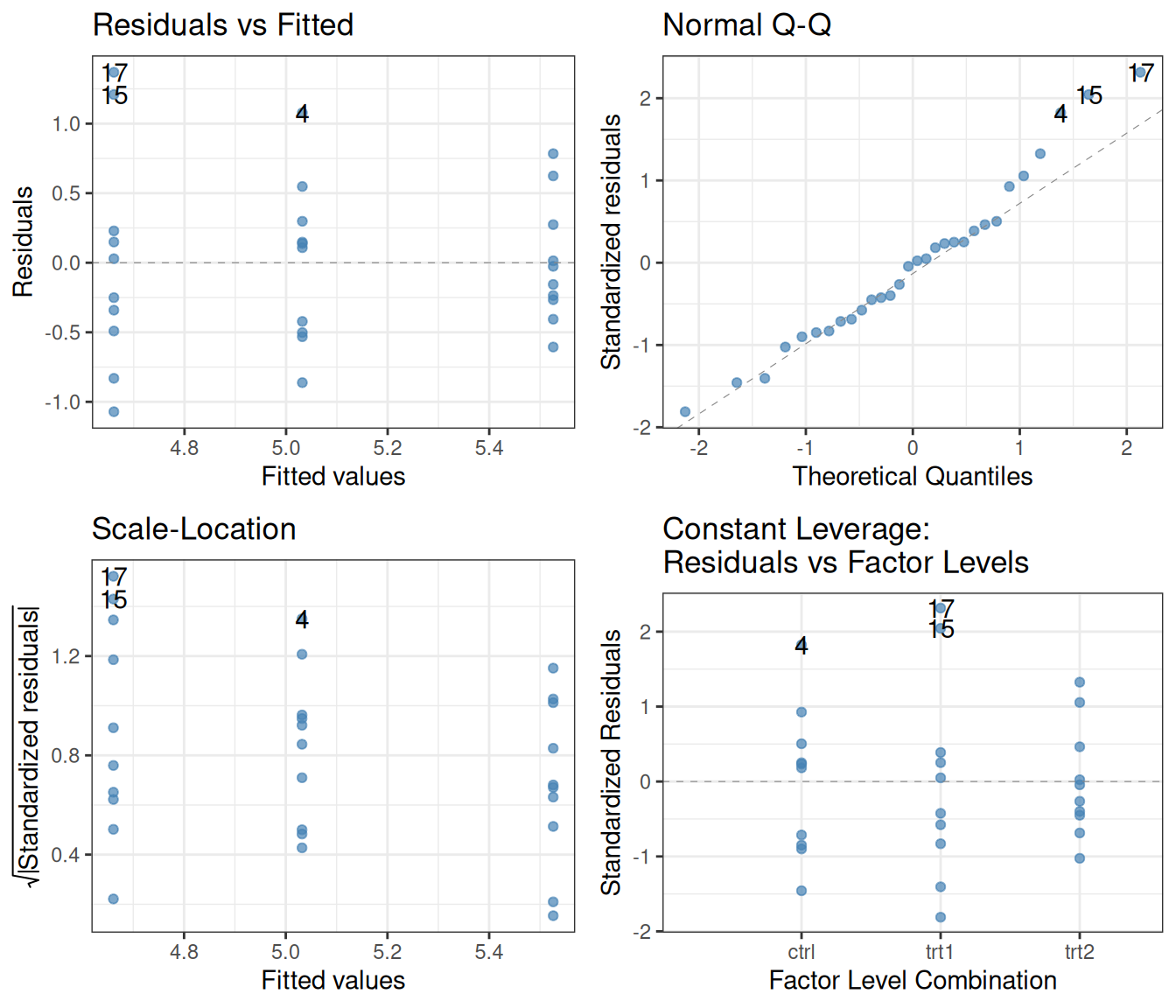
Since ANOVA is just linear regression in disguise, the same assumptions must be fulfilled about the residuals: their variance should not depend on the group, they should be independent, and they should be normally distributed. We can use the same diagnostic plots as we did in Section 11.3:
The only difference is that, since the data are arranged in groups, the fitted values can only take on well-defined discrete values—the inferred means in each. Otherwise, the plots are read and evaluated just as before. In this case, we can see that the assumptions are fulfilled beautifully: the residuals have equal variance in the groups, there is no trend in them, and the quantile-quantile plot shows that they are normally distributed.
12.5 Exercises
The file daphnia_growth.csv contains data on the growth rate of Daphnia populations that are infected with various parasites. There are four groups of observations: the control (no parasites), infection with Metschnikowia bicuspidata, infection with Pansporella perplexa, and finally, infection with Pasteuria ramosa. Each group has ten replicate observations. Are growth rates affected by parasite load?
Before doing any tests, visualize and explore the data, and make sure you have a solid expectation for the results of any statistical analysis.
Answer the question whether growth rates affected by parasite load by first applying a non-parametric test (and a subsequent non-parametric post-hoc test if needed).
Next, apply a parametric test in the same way: by applying the test and running post-hoc tests if needed.
Do not forget to create diagnostic plots, to see if the assumptions behind the parametric test are satisfied to an acceptable degree. Is that the case? And do the results from the parametric and non-parametric tests agree with one another?
In ponds.csv, measured acidity data (pH) is reported from four different ponds. Do the ponds differ in acidity, and if so, which ones from which others? Answer using both non-parametric and parametric tests, with appropriate post-hoc analyses. Check whether these different methods of analysis agree, and make sure that the assumptions behind the parametric test are satisfied using diagnostic plots. (Note: in this dataset, some values are missing.)
In Chapter 13 we will see examples where multiple independent factors are varied, and each possible combination results in a separate group. For example, if the effects of three different dosages of vitamin C are examined on the tooth growth of Guinea pigs, and the vitamin is also supplied in two distinct forms of either orange juice or raw ascorbic acid, then there will be \(3 \cdot 2 = 6\) groups, defined by the two factors of dosage and form of supplement.↩︎
The Kruskal–Wallis test is sometimes referred to as “non-parametric ANOVA”. While this is perfectly fine as a label, one should be aware that it is, strictly speaking, a misnomer: the Kruskal–Wallis test does not rely on computing variances at all.↩︎